遇上这个问题比较凑巧。
tinyco 是接触了几个业务项目后,才诞生的,目的是并发高性能,开发高效率。单进程服务虽然简单,但想要高并发肯定需要多进程,nginx 为我提供了很好的思路。
nginx 多进程同时服务的基本思路是在监听端口后,fork 出几个子进程,再通过竞争关系保证任意时间点只有一个进程在 accept 新进的连接,从而多个进程能同时服务。当一个进程抢到锁后,会将 listenfd 放入 epoll/select 中,从而有新的连接的时候,该进程会被唤醒。
为什么不这样做?所有子进程将 listenfd 都放入 epoll 中。这样做,在较低版本的系统上会有惊群的问题。同样,所有子进程都同时 accept 一个 listenfd,同样较低版本会有惊群的问题。惊群会导致系统 CPU跑得很高,只要很小的并发量就会吃满 CPU。
所以,nginx 保证只有一个进程将 listenfd 放入 epoll/select 中,为的就是防止惊群。但是,当我在压测 tinyco 性能的时候,表现却让我很疑惑,同样的并发,nginx 的 CPU消耗低很多,而且每个的 CPU占用很平均。tinyco 在一开始确实采用上述和 nginx一样的做法,但似乎还是遇上了惊群。
通过 perf top 来看,CPU的消耗主要在 mspin_lock,看来是内核在竞争某个共享资源导致的。
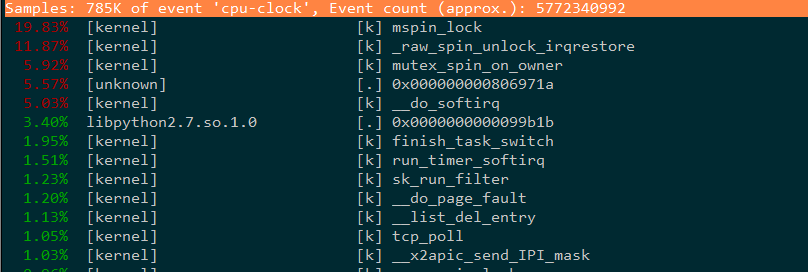
通过查看调用栈,才关注起 epoll 这个系统调用的背后。一开始,tinyco 确实是在初始化 epoll 资源后,才 fork 出子进程的。epoll_create 调用后会返回一个 fd,该 fd 标记了内核中的某个资源,对于 epoll 来说应该就是一颗红黑树了。如果父进程创建了 epoll资源后 fork了子进程,那么所有子进程包括父进程都会共享这一资源,势必这颗红黑树会有互斥访问的保护。惊群的问题迎刃而解。势必在有新的连接过来的时候,所有进程的 epoll_wait 都被惊醒(返回),所以压测的时候不断有新的连接来,所有的进程都不停的被唤醒,CPU很快被吃满。
在优化过后,解决了惊群的问题,即把 epoll_create 放在 fork 后。
这样看来,accept,epoll_wait 都会有惊群的问题。互联网上搜索资料发现,新的系统(4.5 以上)有方法避免这些问题,相信不远的未来可以编写一个高性能的服务器会变成一个简单的事情。
16 August 2017 会持续更新